


Stable Diffusion AI绘画资源和教程导航
Stable Diffusion是目前最火的AI绘画工具之一,它是一个免费开源的项目,可以被任何人免费部署和使用,而不需要支付任何费用。通过提供一句文本提示和调整相关参数,Stable Diffusion可以生成非常精美的图像,从而对传统画师的绘画质量产生了很大的冲击。
Stable Diffusion的优点不仅仅在于它的高效和实用性,它的开源性也为用户提供了更多的可能性。在GitHub等全球最大的开源社区中,用户可以上传自己的代码供他人使用,并且可以从其他开源项目中获取灵感和资源,这也是Stable Diffusion能够不断发展和进步的原因之一。
Stable Diffusion|教程内容
本套教程包含内容教多,主要是围绕Stable Diffusion WebUI进行讲解。理论内容、实现过程、Stable Diffusion WebUI的安装部署、界面介绍、功能讲解、模型下载安装、常见报错问题解决,以及SD的主流插件ControlNet、3D Openpose Editor等,最后也会对大家最关心的AI绘画模型训练这一块有所教学。
前言
本文为Stable Diffusion的全方位教程目录,其中链接至其它文章页面的内容均会实时更新。
因为目前网络上对于Stable Diffusion的讲解太过于笼统,或者太过于深入,导致很多初学者难以理解其到底是什么意思,所以本站对网络上的部分内容进行二次整理,结合了自己的理解进行再次修订。如果你是一个AI绘画方面的小白,那么你可能通过本文的教学有所收获。
本套教程依然遵循于本站开源原则,免费开放给大家学习使用,无广告、无会员制、无需付费、没有回复可见的隐藏内容。
毕竟本站只是个人在维护,所以可能对于部分内容学习精力有限,如果站长对哪一部分内容的理解存在偏差或教学错误,欢迎各位进行指正,谢谢。
技术交流
本站已开放AI技术交流论坛,如果您在学习过程当中遇到问题,可在本论坛发帖求助。
【点击这里前往论坛】
关于
唉,关于这个网站,其实基本就是靠爱心发电,买服务器、买CDN加速、买域名、巨大的时间成本投入,而且这也不是公司和团队在做,而是个人网站。我不理解为什么那么多人复制本站的内容却连一个链接都不愿意留下,我这里刚发表完就已经被盗用至微信公众号去申请了原创,真的很让人无语。
我这里不是不让转载,也不是不让复制,只是希望可以在转载的时候保留一下来源出处即可,但目前来看,这却是一种奢望,国内各站长和自媒体创作者为了流量毫无底线可言。迫不得己,给每一张图片添加了本站的水印,本站知道这会影响大家的阅读体验,但这也是实属无奈,希望各位谅解。
什么是AIGC?
AIGC,全名“AI generated content”,又称生成式AI,意为人工智能生成内容。例如AI文本续写,文字转图像的AI图、AI主持人等,都属于AIGC的应用。
AI绘画的发展过程
AI绘画的诞生之初,所能绘画出的作品都像儿童画一样歪歪扭扭,速度甚至是几天才能画出来一张图,于是研究AI绘画的技术人员开始研究怎样去提升绘画速度,因为只有不断的提升绘画速度才可以不断迭代优化后续版本。经常一段时间的训练和调整之后,终于可以画出非常简单但难以控制的图像,又经过非常多次的升级迭代,终于可以达到正常绘画的结果。
AI的发展速度
日新月异,我时常会感叹,也庆幸自己诞生在这个拥抱AI的时代,就像石器时代突然演变成了蒸汽时代。
在2022上半年之前,我一直认为AI只是大公司所吹嘘的Siri语音助手,那些没有任何用途的交互简直侮辱了AI这个词。但是自从2022年下半年开始,随着Stable Diffusion和ChatGPT的出现,我才知道AI已经来了,而且来得非常突然。目前为止,对于国内来说,70%的人还不知道Stable Diffusion和ChatGPT,因为大多数人都认为这距离自己很遥远,自己并不会从中获利,而且学习过程复杂。这就像之前的我一样目光短浅,但是AI真的难以使用吗?并不是这样的,你不需要去了解AI是如何编写和运作的,你只需要搭乘这辆AI的列车,就可以快速提升工作效率,因为乘客是不需要知道列车如何产生动力和控制方向的,你只要没有买错票就好。
AI绘图目前有哪些可以实现的功能?
- 文生图
- 通过文字描述凭空生成一张图像
- 图生图
- 根据一张已有的图像调整或修改成另一张图像
- Tag推理
- 通过SD插件可以反推出一张图片内的各项信息,比如可以获得图像内的男女、人数、物品、场景等,这有助于模型训练。
- 人物训练
- 通过一个人物的多张照片训练出该人物的模型,根本该模型生成指定人物的各种图像。
- AI训练需要足够多的人物素材,各个角度的素材图片越多,所训练出的效果越好。
- 人物训练最低需要10张照片,画风学习最低需要50张照片。
- 风格训练
- 通过每个画师的多张作品图片,训练出基于该画师的绘画风格。
- 姿态控制
- 通过特殊插件可以控制人物的手势、姿势等内容的生成效果。
- 语义分割
- 可以对场景内的多个元素主体进行区块分割,识别房屋、天空、场景环境等内容。
AI目前无法做的事
- 无法通过一张图片学习达到很好的效果,这里有一个专业术语叫作
one shot。 - 对于手部的姿态虽然可以控制了,但是还无法完全可控。
- 对于脚部的姿态目前可自定义部分较少。
- 表情只能通过文字进行调整,但效果甚微。
目前的主流AIGC产品
| 名称 | 计费方式 | 用户数量 | 发展速度 | 绘画效果 | 使用方式 |
|---|---|---|---|---|---|
| Stable Diffusion | 免费开源 | 非常多 | 迅速 | 中上 | 自由部署 |
| MidiJourney | 按张收费 | 较多 | 缓慢 | 较好 | 在线使用 |
| Dall·E | 按API收费 | 较少 | 极其缓慢 | 一般 | API调用 |
通过对比我们可以发现,Stable Diffusion是目前主流绘图工具中的最优解,因为它是一个免费开源的项目,可以被任何人免费部署和使用,且不需要支付任何费用。
Stable Diffusion的优点不仅仅在于它的高效和实用性,它的开源性也为用户提供了更多的可能性。在GitHub等全球最大的开源社区中,用户可以上传自己的代码供他人使用,并且可以从其他开源项目中获取灵感和资源,这也是Stable Diffusion能够不断发展和进步的原因之一。
闭门造车终究会影响其发展速度。正如 OpenAI 已经不再 open 一样,如果 OpenAI 是开源的,那么将会拥有一些更加强大的功能,并会有无数开发者为其提供魔改的功能。
版权问题
目前各国法律对于AI的创作版权问题界定还比较模糊,但是美国已经出台相关法律,规定AI所绘制的图像不受版权保护。
- 对于开源的Stable Diffusion来说,图像版权为工具的使用人所有。
- MidiJourney则需要购买高级会员,版权才会归AI创作者所有。
- 关于Dall·E目前没有对版权这一块进行详细说明。
硬件要求
推荐配置
- 显卡:Nvidia 2060或后续新出显存在8G以上的显卡
- 内存:16G或以上
- 硬盘:固态硬盘
- CPU:无要求
最低配置
- 显卡:Nvidia独立显卡4G显存
- 硬盘:机械硬盘
- 内存:8G及以上
- CPU:无要求
不推荐的配置
AMD,因为该显卡不支持CUDA。CUDA可以理解为Nvidia(英伟达)专门为自家显卡推出的算力软件。如果您的电脑不支持CUDA,那么您只能通过CPU来进行运算。虽然CPU的运算速度肯定比GPU要慢很多,但它具有局限性,无法进行高并发的计算。
我们可以将GPU理解为100个小学生,CPU理解为1个数学老师。虽然小学生不如数学老师那样厉害,但是如果您有100道非常简单的加减法数学题要交给他们去做,那么肯定是这100个小学生完成的效率更高。而这100个小学生就相当于是支持高并发计算的GPU,数学都是相当于是CPU。
教程目录
为方便阅读,教程目录中的Stable Diffusion将以SD为简称,请尽量按顺序学习。
| 文章名称 | 内容描述 | 推荐 指数 |
链接 |
|---|---|---|---|
| SD的工作原理 | SD是生成图像的原理是什么? | 可选 | 前往 |
| SD和SD Webui是什么关系? | 本文介绍关于什么是SD WebUI | 可选 | 前往 |
| 什么是SD本地化部署? | 关于本地化部署的优缺点介绍 | 可选 | 前往 |
| 本地化部署SD WebUI|N卡 | 英伟达显卡Windows本地化部署SD教程 | 重要 | 前往 |
| 本地化部署SD WebUI|A卡 | AMD显卡Windows本地化部署SD教程 | 可选 | 前往 |
| 本地化部署SD WebUI|MacOS | MacOS系统本地化部署SD教程 | 可选 | 前往 |
| SD安装常见报错解决方法 | 已汇总本站网友提供的所有报错信息 | 可选 | 前往 |
| SD汉化教程 | SD中文界面设置教程 | 重要 | 前往 |
| 如何在局域网或公网访问SD | SD局域网或公网远程访问并设置密码 | 可选 | 前往 |
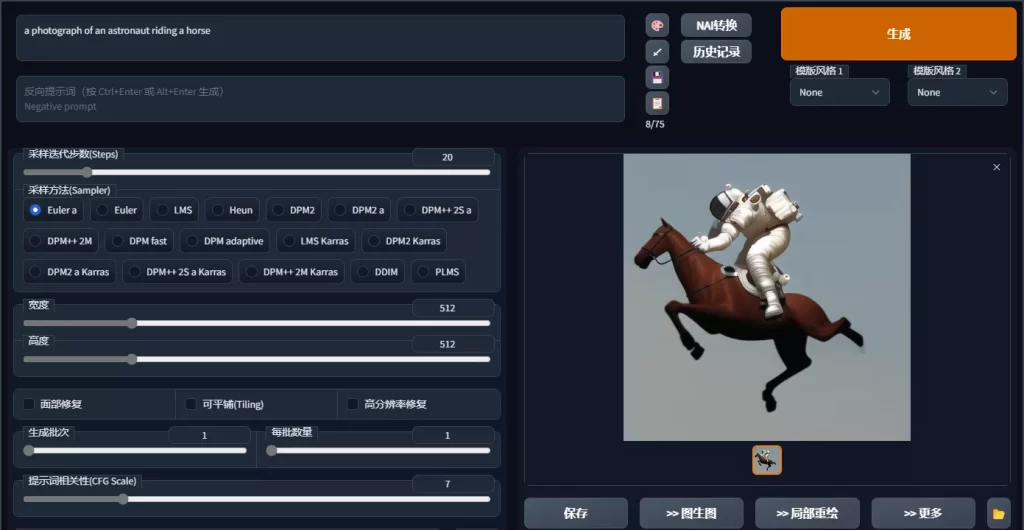
| SD文生图 | 认识SD基础界面以及各参数详细讲解 | 重要 | 前往 |
| SD的Prompt提示词高级方法 | 介绍一些关于Prompt提示词的技巧 | 重要 | 前往 |
| SD模型的基础知识 | 关于常见模型以及后缀讲解的基础知识 | 重要 | 前往 |
| SD图生图 | 关于以图生图|反正推理|涂鸦重绘等 | 重要 | 前往 |
| SD模型合并 | 关于模型合并 + 信息提取的相关教程 | 推荐 | 前往 |
| SD的LoRA | LoRA模型介绍与下载 | 推荐 | 前往 |
| SD自动获取模型封面插件 | Civitai Helper2模型信息获取插件 | 推荐 | 前往 |
| 旧版本,已不推荐阅读。 | 前往 | ||
| 旧版本,已不推荐阅读。 | |||
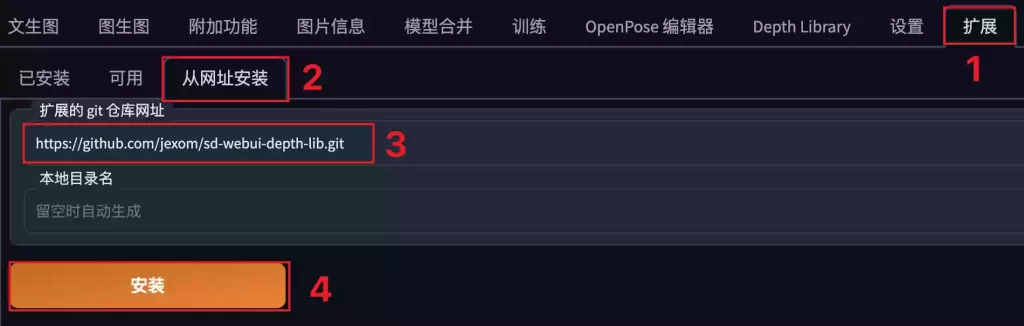
| SD的ControlNet-1.1【上】 | ControlNet安装、下载、部分模型教程。 | 推荐 | 前往 |
| SD的ControlNet-1.1【中】 | ControlNet部分模型和预处理器教程 | 推荐 | 前往 |
| SD的ControlNet-1.1【下】 | ControlNet剩余部分模型和预处理器教程 | 推荐 | 前往 |
| SD插件|Segment Anything | 可自由分割任何物体的插件安装使用教程 | 推荐 | 前往 |
| 旧版本,已不推荐阅读。 | 前往 | ||
| 旧版本,已不推荐阅读。 | 前往 | ||
| SD视频转动画 | SD+ControlNet将视频转换为动漫风格化 | 可选 | 前往 |
| SD生成缩放视频 | 通过SD生成多张无缝衔接的图像缩放视频 | 可选 | 前往 |
| SD插件介绍 | 编写中 | 重要 | |
| SD插件:Photopea | 可以将PS内置在SD中,并且和PS交互。 | 可选 | 前往 |
| SD|LoRA模型训练|准备工作 | 关于图像素材处理与Tag自动打标等介绍 | 重要 | 前往 |
| SD|LoRA模型训练|详细教程 | 关于训练工具的安装与详细参数讲解教学 | 重要 | 前往 |
| SD|LoRA模型训练|极速训练 | 抛弃前置知识,极速训练一个LoRA模型。 | 重要 | 前往 |
模型下载
| 类型 | 版本 | 描述 | 链接 |
|---|---|---|---|
| 官方模型 | 1.5 | 适合生成写实类风格 | 前往 |
| NovelAI | 泄漏版 | 适合生成二次元风格 | 前往 |
| ControlNet | 3.0 | 适合生成半写实类风格 | 前往 |
| LoRA模型-P1 | 1 | 第一批LoRA热门模型 | 前往 |
| LoRA模型-P2 | 2 | 第二批LoRA热门模型 | 前往 |
| LoRA模型-P3 | 3 | 第三批LoRA热门模型 | 前往 |
| LoRA模型合集 | 0 | Trauter_LoRAs游戏模型 | 前往 |
相关网站推荐
| 网站 | 描述 |
|---|---|
| 本站论坛 | 如果你不方便自己下载模型,可前往本站论坛发帖求助。 |
| Civitai | 最常用的模型下载网站,但是需要魔法才可以访问。 |
| Hugging Face | 偶尔个别模型作者会发布在此网站内,极个别情况下使用。 |
总结
Stable Diffusion是一个非常实用的AI绘画工具,它的免费开源性和高效实用性为用户提供了更多的可能性。如果您对AI绘画感兴趣,或者想要使用Stable Diffusion来实现自己的创意,上述相关资源和教程将会对您很有帮助。
![图片[3]-Stable Diffusion|全方位教程指南 - 如意-如意](https://rueee.com/wp-content/uploads/2023/07/ec2008099a97f4f742090ac6423c68ef-4.jpg)
评论 (12)
![图片[17]-Stable Diffusion|全方位教程指南 - 如意-如意](https://openai.wiki/wp-content/uploads/WeChat_AI-Magic-300x125.webp "WeChatAIMagic openAI")








可以写点关于炼丹的吗?
为博主点赞!!!我支持你!
为站长点赞
为博主点赞,感谢博主的无私知识分享。
感谢站长的付出,非常好的文章,很受用!
如果有问题,请前往论坛发贴,我会在论坛为大家处理问题。
之前只是粗略看了一下,突然发现这里都是干货
@hp_zerolan 感谢认可🙏
为博主点赞, 信息收集整理的真好
站长可以更新下,目前midjourney是包月收费,生成图片版权应该是归客户自己。
@Faster 好的,多谢指正。
谢谢,站长分享。