


最近NovalAI的部署教程随处可见,可基本都是windows本地和colab白嫖google羊毛的、更多面向使用者 想要自己在Linux服务器上部署、找了一圈都没满意的、官方的一键脚本没有考虑国内网络的环境、很多大佬也不屑于写诸如此类的东西、导致踩了无数的坑才成功部署 希望借此文来帮助和我一样想部署在Linux服务器上的同学们,也好对AI黑盒里的技术窥视一番
- 正文开始前先讲一讲、目前为止SD的部署方案汇总
- colab(科学上网 谷歌账号 包含两种ui界面的colab)
- windows(本地)
- Linux+SDWebUi 本文内容
- 利用autodl平台自带的公网ip映射服务( 强烈推荐,没有有效时间限制,访问速度快)
- gradio (负责自动化生成部署生成一个网页,72小时后失效)
- Linux 前后端分离 docker nginx postgresql (需要自己的公网ip或域名 显存 内存 要求最高)
10.29号更新:优雅的远程开发工作流
![图片[1]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://rueee.com/wp-content/uploads/2023/03/v2-e3718e04aa8353308da4429c38bcf3be_r.jpg)
正文部分:Linux+SDWebUi 部署NovelAi
- 用到的工具
- aria2 (类似于curl的下载软件 用于后面下载模型文件)
- 自行安装的依赖(就是把依赖中的硬骨头先一个个手动安装 别的借助requirement.txt自动安装)
- pytorch cuda
- 11.3号更新 gradio3.8已经可以用pip正常下载
- 用到的开源组件
- stable-diffusion(sd本体、webUI就是封装了个UI(当然还集成了一众优秀的功能)让我们能通过可视化界面而不是通过命令行参数使用SD绘画创作)
- BLIP (interrogate CLIP的依赖 负责img2img中描述input图像内容并输入至prompt框)
- taming-transformers (stablediffusion的高分辨率图像的生成)
- k-diffusion(为SD提供samplers(采样器)SDE(随机微分方程)和ODE(常微分方程))
- midas(负责为sd 深度模型提供支持)
更多详情请见
![图片[2]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://rueee.com/wp-content/uploads/2023/03/v2-b8875395032f209a9b4d12d573f9dfbc_180x120.jpg)
开始
TLDR(2023.2.3更新)
制作镜像封装了最新的webUI,内置所有依赖所需的权重文件(考虑到webUI在更换依赖到pytorch 1 .13. 1后性能方面提升显著,也将迎来稳定期,所以做一个全面稳定的镜像方便自己和大家使用),内置anything4.5模型、常用vae权重文件、以及一些常用插件
无需任何编程基础 注册autodl账号 后直接照着下面视频使用教程操作即可完成部署使用的全过程
使用教程
选用autodl平台的服务器(别的服务器平台基本一致)
- 注册 autodl注册界面(新用户注册会送十块钱)
- 选实例 参照colab谷歌给我们白嫖的机器配置 (autodl 性价比推荐 内蒙古 A5000 24G显存 )
- 选镜像 直接miniconda python3.8 cuda11.3
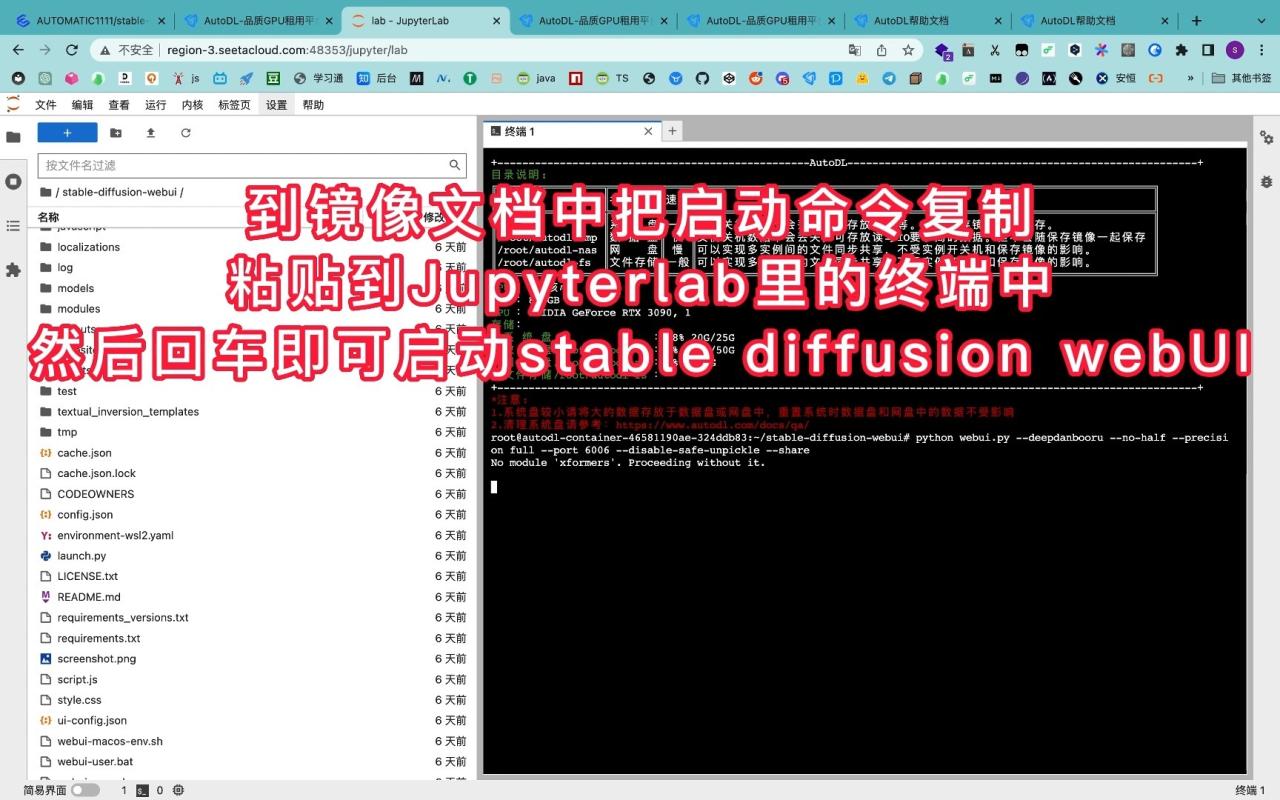
- (2023.1.25 更新 已封装了webUI全套镜像内置所有依赖所需的权重文件 内置anything4.5 复制镜像创建实例后 直接在webUI目录下执行启动命令即可启动镜像cuda11.7 pytorch 1.13.0)
- 点击我的实例-快捷工具-jupyterLab 启动页点击终端新建一个终端
下载安装依赖
- 进入数据盘路径
cd autodl-tmp - 加速github下载速度(找到自己的区并在终端输入相应的语句 )
- 更新下apt下载工具
apt update
- 补充安装python3环境
sudo apt install wget git python3 python3-venv
- 用pip安装 pytorch 和cuda (服务器conda有bug pip默认就加过速了 所以直接用pip下载安装)
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
- 检查cuda和pytorch是否可用
python -c "import torch; print(torch.cuda.is_available())"
- 下载aria2 类似于curl 下载软件 用于后面下载gradio和模型文件
apt install aria2
- 11.3 号更新 gradio更新到 3.8 版本 现在可以直接通过pip 从远处包仓库中下载安装 pip install gradio==3.8即可
- gradio (负责自动化生成部署生成一个网页(前端和中间件去代理绘图程序API),使你能通过http和前端界面与后端API交互)
- 11 .27 号更新 webui又加了一堆依赖… 其中torchsde会出现pip下载过程镜像源中找不到对应包的问题 torchsde是webui近期更新后增加的依赖 可以去pypi 上搜torchsde 然后将安装包whl文件下到机子上 然后pip install 加刚才的whl文件名 手动安装
下载Stable-Diffusion-Webui框架和SD绘画各个步骤用到的模型框架
Stable Diffusion WebUi简称 SDWebUi,web UI是一个基于 Gradio 库的 Stable Diffusion 浏览器界面。
- 下载 web ui 框架并进入路径
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.gitcd stable-diffusion-webui
- 下载 StableDiffusion(绘图) 和 CodeFormr(脸部修复)
mkdir repositoriesgit clone https://github.com/CompVis/stable-diffusion.git repositories/stable-diffusiongit clone https://github.com/CompVis/taming-transformers.git repositories/taming-transformersgit clone https://github.com/sczhou/CodeFormer.git repositories/CodeFormergit clone https://github.com/salesforce/BLIP.git repositories/BLIP
- 下载安装Stable Diffusion的依赖
pip install transformers==4.19.2 diffusers invisible-watermark --prefer-binary
- 下载安装k-diffusion
pip install git+https://github.com/crowsonkb/k-diffusion.git --prefer-binary
- 下载gfpgan 可选 负责脸部修复face restoration
pip install gfpgan
- 安装之前下载的CodeFormer的依赖
pip install -r repositories/CodeFormer/requirements.txt --prefer-binary
- 安装 web ui框架的依赖
pip install -r requirements.txt --prefer-binary
- 更新numpy到最新版本(因为之前很多包都会引用到
numpy所以为了保证版本统一,在此更新为最新版)pip install -U numpy --prefer-binary
下载模型文件
如需别的模型请自行替换(也可以多个并存,根据需要在画图过程中在页面左上角切换) 位置一律放在/stable-diffusion-webui/models/Stable-diffusion/ 下
10.19号成功解决模型切换的问题后、现在可以控制相同prompt seed,快速对照SDv1.4和NovelAI生成效果.
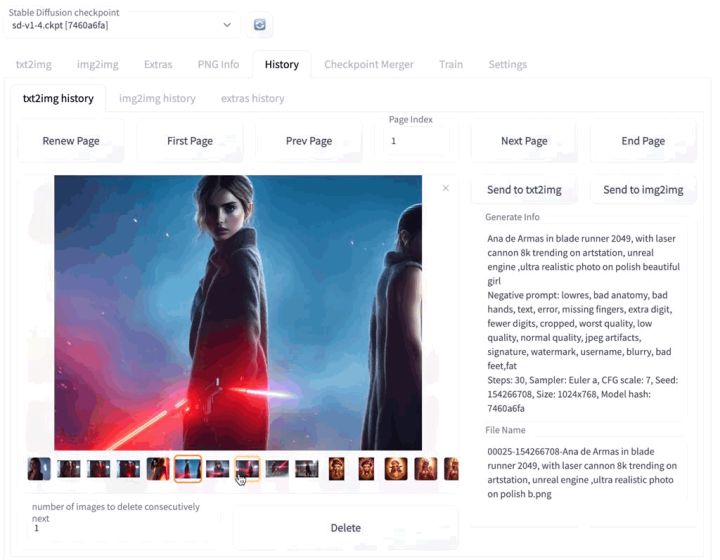
NovelAI(10.20号更新 因为链接都有期限 大家最好自己备份下 ) 更多模型可见
aria2c --summary-interval=10 -d ./models/Stable-diffusion/ -x 3 --allow-overwrite=true https://pub-2fdef7a2969f43289c42ac5ae3412fd4.r2.dev/animefull-latest.tar因为这个链接下的是tar压缩包 所以需要tar xf 解压 并rm 删除压缩包 (具体命令自行网上查阅)注意: 最后ckpt一定要在 /models/Stable-diffusion/目录下
- tar xf animefull-latest.tar
- rm animefull-latest.tar
Stable-diffusion 1.4
去HuggingFace去下载(注册账号 同意条款 然后就能看到下载链接)
CompVis/stable-diffusion-v-1-4-original · Hugging Face
(10.23日更新)Stable-diffusion 1.5
runwayml/stable-diffusion-v1-5 · Hugging Face
运行
下面是运行程序的两种方法 (10.18日更新 :添加一种更好的方法,即利用autodl平台的公网ip映射服务来实现部署服务,无需借助gradio,强烈推荐)
方法一:利用autodl平台自带的公网ip映射服务(没有有效时间限制,访问速度快)
10.28号更新、为防止该服务被滥用、现在在autodl平台使用该服务需先实名制、所以使用时请合法合规
AutoDL为每个实例都预留了一个可对外暴露的端口,技术实现为将实例中的6006端口映射到公网可供访问的ip:port上,如果您自启动的服务带有Web网页那么点击访问后就可以打开Web网页。如果您启动的是API服务,那么通过打开的地址进行API调用即可(因为没有Web网页,打开后不会有任何网页显示)
- 1 在终端中输入运行下列命令–port 6006将程序部署在服务器本机的6006端口
COMMANDLINE_ARGS="--medvram --always-batch-cond-uncond --port 6006" REQS_FILE="requirements.txt" python launch.py- 2 找到控制台界面,找到你实例的自定义服务按钮,点击访问即可进入autodl平台帮我们映射到公网的网站(之后可以从其他设备的浏览器访问这个网址来使用部署的绘画服务)
![图片[5]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic3.zhimg.com/80/v2-cf2a56fad275dd49a0eaef0930277dca_720w.webp)
- 如需了解更多,可在autodl帮助文档的这个子页面中找到 https://www.autodl.com/docs/port/
方法二:SSH端口转发(ssh隧道) 10.28号autodl 公网映射监管收紧后 推荐该方法 安全系数最高
访问一个远程机器上没有公开的端口。这种情况下可以使用SSH隧道技术(或者叫端口转发)将所需的远程端口 “转发 “到你的本地机器,然后就可以通过访问自己机器的本地端口来使用远程程序的相应端口上的服务
限于篇幅控制、具体操作见下文中的具体演示
![图片[7]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic1.zhimg.com/80/v2-89575d9803519dba7b28b276fc790ab0_720w.webp)
方法三:利用gradio提供部署服务(每次可使用72小时,相较于第一种方法访问速度会慢些,安全性差)
如果你用的不是autodl平台,别的平台估计也有类似的公网ip映射服务 (我猜的2333) 如果没有而又想要通过URL给他人使用演示,就只能借助gradio这种方法了
- 在终端中输入运行下列命令
COMMANDLINE_ARGS="--medvram --always-batch-cond-uncond --share" REQS_FILE="requirements.txt" python launch.py
–share参数 会得到一个以.app.gradio 结尾的链接,这是在协作中使用该程序的预期方式。(不加 –share 没法远程使用)
2. 访问上面的链接即可开始使用
运行程序的一些命令行参数及解释
| 命令行参数 | 解释 |
|---|---|
| –xformers | 使用xformers库。极大地改善了内存消耗和速度。Windows 版本安装由C43H66N12O12S2 维护的二进制文件 |
| –force-enable-xformers | 无论程序是否认为您可以运行它,都启用 xformers。不要报告你运行它的错误。 |
| –opt-split-attention | Cross attention layer optimization 优化显着减少了内存使用,几乎没有成本(一些报告改进了性能)。黑魔法。默认情况下torch.cuda,包括 NVidia 和 AMD 卡。 |
| –disable-opt-split-attention | 禁用上面的优化 |
| –opt-split-attention-v1 | 使用上述优化的旧版本,它不会占用大量内存(它将使用更少的 VRAM,但会限制您可以制作的最大图片大小)。 |
| –medvram | 通过将稳定扩散模型分为三部分,使其消耗更少的VRAM,即cond(用于将文本转换为数字表示)、first_stage(用于将图片转换为潜在空间并返回)和unet(用于潜在空间的实际去噪),并使其始终只有一个在VRAM中,将其他部分发送到CPU RAM。降低性能,但只会降低一点-除非启用实时预览。 |
| –lowvram | 对上面更彻底的优化,将 unet 拆分成多个模块,VRAM 中只保留一个模块,破坏性能 |
| *do-not-batch-cond-uncond | 防止在采样过程中对正面和负面提示进行批处理,这基本上可以让您以 0.5 批量大小运行,从而节省大量内存。降低性能。不是命令行选项,而是使用–medvramor 隐式启用的优化–lowvram。 |
| –always-batch-cond-uncond | 禁用上述优化。只有与–medvram或–lowvram一起使用才有意义 |
| –opt-channelslast | 更改 torch 内存类型,以稳定扩散到最后一个通道,效果没有仔细研究。 |
Q&A(自己碰到的bug 欢迎评论区添加)
- Q:torchsde报错找不到合适版本
- A:torchsde是webui近期更新后增加的依赖 可以去pypi 上搜torchsde 然后将安装包whl文件下到机子上 然后pip install 加刚才的whl文件名 手动安装
- Q:系统环境混乱 重置
- A:关机更换镜像 再开机
- Q:报错未知参数 scale
- A:gradio更新到最新3.5
- Q:出现
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed.报错 - A:不用管,倒数第三步解决该问题
- Q:换别的模型报错(10.19号更新)
- A:10.19号更新 确定为之前版本Stable Diffusion Webui的bug 在Stable Diffusion Webui 路径下 执行 git pull 命令拉取最新版webui 即可解决(估计是10.18号的官方更新代码中修复的)
- Q:每次重启机器后如何再次运行程序
- A:cd 到webui路径下,输入最后那串命令(github加速 export 环境变量在当前终端关闭后会失效 所以重启后需再次执行)
- Q:autodl系统盘占用特别多,不知道怎么回事就满了
- A:
![图片[8]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://rueee.com/wp-content/uploads/2023/03/v2-354970e0a10610a48cb08a363f64744f_180x120.jpg)
- Q:export 环境变量加速github下载后,本地端口转发 gradio安全性报错
![图片[9]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic3.zhimg.com/80/v2-e627c7bc7090443b4675c024193e0a9e_720w.webp)
- A:到gradio源码里把检查判定逻辑那几行代码注释掉(每次git pull 更新webui前记得把注释取消)
![图片[10]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic3.zhimg.com/80/v2-b7b9f815d3743c5e30586f3e3d9de236_720w.webp)
参考链接
ps: 是的,封面就是用部署完的服务器画的 ╰( ’ ’ )╮
更新动态(后续会按技术原理部署、使用训练、新闻动态等分类整理重构下,便于大家阅读索引)
2023.1.25 最新的webUI 又更新了环境需求 要pytorch 1.13.1 pip镜像源里尚无 需要自行去pypi下载
为方便大家更新 已全套打包上传百度云 cp38 linux 和我环境一致可以直接下载安装
- 先卸载 这三个
- 然后在pip install 加文件名 本地安装
![图片[11]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://rueee.com/wp-content/uploads/2023/03/v2-0478db1797e9e10ea1314fd5abc3aaf6_720w.webp.png)
2023.1.9 新年第一篇,讲讲如何找到心仪的模型
![图片[12]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://rueee.com/wp-content/uploads/2023/03/v2-b2faeea52b2d7a2bda45cf815ff4b215_r-1.jpg)
11.27 stable diffusion 2.0近日已发布 因为使用方法与之前略有不同 所以介绍一下
- 下载模型文件 768-v-ema.ckpt
stabilityai/stable-diffusion-2 at main
![图片[13]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic2.zhimg.com/80/v2-56853fa21324bc8bccbcfc3a82539325_720w.webp)
2.把ckpt文件放入 models/Stable-Diffusion 路径下
3.下载SD2.0模型配置文件 stablediffusion/configs/stable-diffusion at main · Stability-AI/stablediffusion 即下载下图中的v2-inference-v.yaml,并将其放在与检查点相同的地方(models/Stable-Diffusion 路径下),重命名为相同的文件名(即如果你的检查点被命名为768-v-ema.ckpt,配置应被命名为768-v-ema.yaml),至此就可正常使用2.0模型 (不过个人感觉效果不是很好)
![图片[14]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic2.zhimg.com/80/v2-014568c4b28e273396c100a2c1236499_720w.webp)
11.27 deepdanbooru 近日在webui中提供了pytorch实现的版本
(之前的是由tensorflow实现 所以需要用户机子上同时装pytorch和tensorflow依赖过于庞大)在webui img2img 选项页第一次点击deepdanbooru时程序会自动下载pt检查点文件并调用(速度可能很慢 可以用aria2c 事先下好放到相应路径下 下载地址为 https://github.com/AUTOMATIC1111/TorchDeepDanbooru/releases/download/v1/model-resnet_custom_v3.pt )
![图片[15]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic3.zhimg.com/80/v2-c67e481ffeccf2bbf7bee77eb26f6d7e_720w.webp)
11.18日更新 奉上大家期盼已久的 DreamBooth全套教程
![图片[16]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://rueee.com/wp-content/uploads/2023/03/v2-47182ae4cc323a0f21cf8f5a4459e1a3_r.jpg)
11.11更新 万众期待的dreambooth自训练现在可以在webUI里完成(作者就是曾经提交pr想要将dreambooth merge到webui主体里的那个大佬,随着webui规模不断庞大,原来的pr合并到主仓库变得不怎么现实,所以作者经过一段时间开发和完善 转而以extension形式提供dreambooth自训练的功能 具体使用将于这两天更新 )
![图片[17]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic2.zhimg.com/80/v2-d5ea6011b0ff58e5013ecdfcbd533f41_720w.webp)
11.1更新 庖丁解牛 Stable-diffusion-webui 插件 脚本 依赖 全方位指南
![图片[18]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://rueee.com/wp-content/uploads/2023/03/v2-b8875395032f209a9b4d12d573f9dfbc_r.jpg)
10.29更新 为防止公网映射服务被滥用、现在在autodl平台使用该服务需先实名,遂推荐SSH端口转发方法部署 操作流程已写更新、可在文章对应位置查看
10.27更新 中文汉化已上线 webui近期将一些非核心功能转为了插件模块单独解耦,你可以在webui路径下的extension文件夹里下载放置你想使用的任意插件,以下列举一些目前为止比较热门的插件的git项目地址(后续会更新具体使用方法)
- 生成视频 3d、2d 模块 :https://github.com/deforum-art/deforum-for-automatic1111-webui
- 美学权重插件(从美学角度优化图片) :https://github.com/AUTOMATIC1111/stable-diffusion-webui-aesthetic-gradients
- 历史图片浏览器(查看软件之前生成的图片):https://github.com/yfszzx/stable-diffusion-webui-images-browser
10.23更新 webui最近更新了Aesthetic Gradients 美学权重功能(以插件形式提供),借助该功能,可以在保持作品原始的总体构图上提高美观度。
(目前测试下来效果不错,下面是拿昨天训练的废稿做的测试,结合hypernetwork使用效果更佳,支持txt2img和img2img)具体可参阅此链接
![图片[19]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic3.zhimg.com/80/v2-6de0beea600acf0aca69bc5e04eaf61a_720w.webp)
![图片[20]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic3.zhimg.com/80/v2-b152c99b4ee4836c95a8316b2ef4a33e_720w.webp)
![图片[21]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://pic1.zhimg.com/80/v2-04607b0b575a0ff28e4d1c5a356839fc_720w.webp)
10.23 更新 sd在hugging face更新了1.5版本
10.19更新 开个新坑 这几天看到各种prompt里很多都有语法错误,要么就是一堆单词拼错 觉得有必要开个魔法教程 (英语教程)
![图片[22]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://rueee.com/wp-content/uploads/2023/03/v2-3c90daefa4081088250165d8ef8231f4_r.jpg)
10.21 已更新 hypernetwork自训练的详细教程 (boss tensorflow 闪亮登场) ヾ(*´ ‘*)ノ
![图片[23]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://rueee.com/wp-content/uploads/2023/03/v2-bccfba26bc1231beea735f7d9659d56e_r.jpg)


一些之前写的相关文章
SeASnAkE:计算机英语 前置工具准备 (什么年代了 还传统英语学习呢)
SeASnAkE:Python 机器学习环境配置[conda(miniconda)、 pytorch 、cuda 的下载安装及避坑指南]

![图片[27]-使用stable-diffusion-webui部署NovelAi/Stable Diffusion 保姆级教程、命令解释、原理讲解(colab、windows、Linux ) - 如意-如意](https://rueee.com/wp-content/uploads/2023/03/v2-4812630bc27d642f7cafcd6cdeca3d7a-1.jpg)

![[赞同]](https://rueee.com/wp-content/uploads/2023/03/v2-419a1a3ed02b7cfadc20af558aabc897-2.png)

![[爱]](https://rueee.com/wp-content/uploads/2023/03/v2-0942128ebfe78f000e84339fbb745611.png) torchsde都更有了
torchsde都更有了
![[捂脸]](https://rueee.com/wp-content/uploads/2023/03/v2-b62e608e405aeb33cd52830218f561ea.png)


![[大哭]](https://rueee.com/wp-content/uploads/2023/03/v2-41f74f3795489083630fa29fde6c1c4d.png)










![[拜托]](https://rueee.com/wp-content/uploads/2023/03/v2-3e36d546a9454c8964fbc218f0db1ff8.png)









暂无评论内容